Let's assume you are considering using Cassandra for logs storage or in general, for time series storage. Let's assume your usage pattern is that you store insane amounts of data for three months and you query them rarely, usually when something goes wrong and you need to investigate why. So, you have made business analysis. You have made technical analysis. You made performance benchmarks. You identified clustering and partition keys. You picked the right hardware. You tested how the cluster responds to peaks. You tested the cluster for minute, hour surges. You have been running the cluster in tests for weeks. You are now ready to deploy system to the production.
You are now ready to fail in ~one month. Wait, what?!
Of course, all mentioned steps bring you closer to the success. It's good that there are plenty of great resources on how to design time series model in Cassandra. Just google "
time series design Cassandra".
Surprisingly, the first five of them (dunno about others), don't mention setting the right compaction strategy.
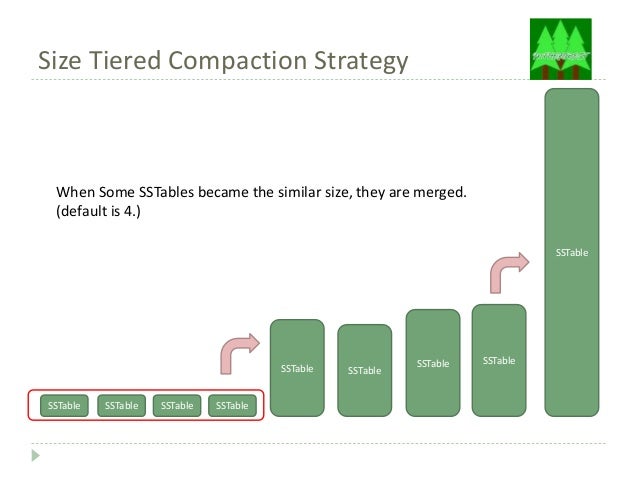
The default compaction strategy (Size Tiered Compaction Strategy)
The default compaction strategy triggers a compaction when multiple SSTables of a similar size are present. To emphasize how evil is that for log storage scenario, let's assume that a week of production logs results in 1x 168GB SSTable, 3 x 42GB SSTables, 3 x 10GB SSTables, etc. After two weeks, the biggest SSTable will be probably still 168GB . That's fine. You have tested the cluster for two weeks of production load, right? The trap is, you want to store logs for three months. Nobody will spend that amount of time hitting the test cluster with production load. After three months, the biggest SSTable will be around 672GB and month after that probably 2688GB. The compaction isn't free. It takes your CPU, it takes your disc IOPS (yes, nice sequential writes, but still).
It will take your life (or rather kill your cluster with pending compactions).
Solution: Date Tiered Compaction Strategy
The date tiered compaction strategy will simply leave, after some time, old SSTables untouched. The same situation described above will translate to having (depending on your use case) for example 10x ~268GB SSTables, or perhaps 100x ~26GB SSTables. No killing compactions on old data! Read about the details here:
DateTieredCompactionStrategy: Compaction for Time Series Data and here:
Date-Tiered Compaction in Apache Cassandra. Yes, queries probably will be a little bit slower.
All in all, invoking this CQL (with carefully chosen consts), will save your cluster:
ALTER TABLE myprecouslogs.myprecioustable WITH compaction = { 'class' : 'DateTieredCompactionStrategy', 'base_time_seconds':'XXX', 'max_sstable_age_days':'YYY' }
and here is how to do it on a live organism:
How to change Cassandra compaction strategy on a production cluster.
BTW. Do you know that there is also
anticompaction?


No comments:
Post a Comment